
GOAT-Storytelling: Arbitrarily Long Story Writing Agent

While there are many story-writing solutions based on LLMs, model-only storywriters cannot give sufficient control over the story, and agent-only code does not work well with untuned models. Today we release our solution to the problem, which lies in using an agent that manages all story elements, GOAT-Storytelling-Agent, and an LLM specifically tuned to work with the agent, GOAT-70B-Storytelling. This combination allows to generate arbitrarily long and interesting stories, movie plots, or books. We open-source model weights and agent algorithm code, as well as give a demo dataset with works generated using the two.
GOAT-70B-Storytelling is a finetuned version of LlaMA 2 70b. It was trained on a mix of instruction and story-writing tasks. While the model itself a good story writer, its main purpose is to work as a part of GOAT-Storytelling-Agent for entertaining and controlled story generation.
LLM storytellers
Long-text generation task is not trivial for current LLM architectures. The main struggle is in attention computation complexity, which is quadratic with respect to the size of a sequence. While some works address this issue by directly modifying attention mechanisms, others focus on ways to create efficient ways to utilize current context restrictions. For example, in (Zhou et al., 2023), authors utilize the ideas behind LSTM, by updating short and long memories with natural language, allowing for long text generation without the loss of context or memory. Authors of (Introducing MPT-7B, 2023) handle the issue of short context length by directly changing vanilla attention and expanding the context size of the LLM up to 65k+ context, as well as training it on the subset of the book corpus, which facilitates the generation of great and interesting stories.
GOAT-Storytelling-Agent
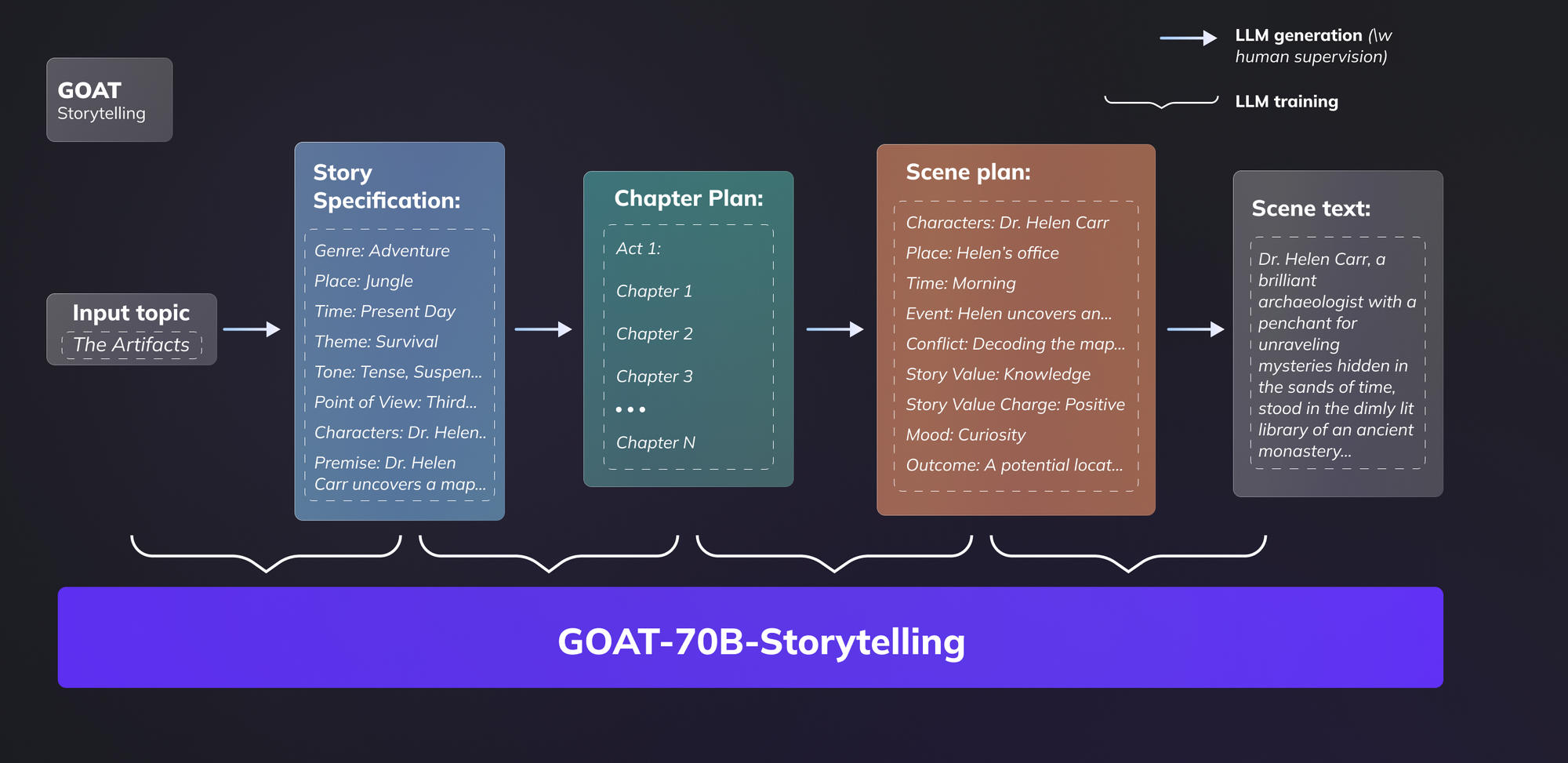
Instead of direct text generation and story creation "on the fly", we follow an "agent-first" approach and shift the paradigm of storytelling toward complex reasoning and planning process, which requires general knowledge about the main characters, their relationships, and the overall trace of the story. After the agent is initialized with a description of a story, it then creates the main plot, timeline, scenario, and characters (or humans can supervise this process by adding their own changes).
Our agent decomposes stories into following elements, inspired by McKee (2010):
- Story - keep only high-level information such as genre, characters, settings, plot, tone, stylistic features, etc.
- Act - only keep the number
- Chapter - event descriptions and story value charges
- Act - only keep the number
- Scene - low-level information such as a list of events, involved characters, settings, mood, story value, its charge, etc. The list of attributes can be expanded by the user.
We prompt an LLM to generate the outlined structural elements of the story in a stepwise fashion. By following a top-down approach, we allow LLM to plan its steps ahead in the story generation while preserving human supervision, where one can modify any part of the plan. Having a complete plan of the story, we now prompt an LLM to actually generate scene text. This is done while preserving access to both short-term memory (recent text) and long-term memory (complete plan of the novel) inside the prompt. We empirically find that current LLMs can handle meaningful generation for no longer than several scenes, which is why a scene is an atomic piece of story in our framework. This way, we break down a story into a sequence of scenes, and then run generation separately for each scene.
We find the proposed structural elements very convenient for many story forms, however, we understand that not all stories can fit into this skeleton. Since our agent library design sparingly follows functional paradigm, one can easily modify the key stages of the agent's algorithm. We also isolate prompt text from the code, so that one can modify attributes of any given structural element (act, scene, etc) by only working with prompts as strings.
GOAT-70B-Storytelling
In addition to the agent, we also release the SFT version of LlaMA-70B, trained on a mix of instruction and storytelling data.
For data collection, from our previous experiments, we found it beneficial to add instruction as well as story-writing tasks in the dataset. We used a positive feedback loop to improve both our model and agent. First, based on our story generation attempts, we identify writing stages that need to be added for the agent, then we obtain more instruction examples of controlled story generation and use it to tune the model. This way, both the agent and model are robust enough to accomodate many writing processes. We reduce our model's bias by training it on a variety of genres and topics.
Training details:
Training was performed on a GPU cluster of 64xH100s. FSDP ZeRO-3 sharding is employed for efficient training. We instruction finetune on a dataset of 18K examples for one epoch with batch size of 336, AdamW optimizer with learning rate 1e-5.
Usage and demo dataset
Our code, implementation, and weights are available on GitHub and Huggingface. To demonstrate the capabilities of the model and agent, we release 20 novellas generated without human supervision requiring only single initial topic for input. The dataset is hosted as an HF dataset - generated-novels.
References
Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs. (n.d.). https://www.mosaicml.com/blog/mpt-7b
McKee, R. (2010, September 28). Story. Substance, Structure, Style, and the Principles of Screenwriting. Harper Collins.
Zhou, W. (2023, May 22). RecurrentGPT: Interactive Generation of (Arbitrarily) Long Text. arXiv.org. https://arxiv.org/abs/2305.13304