
Improving Large Language Models: The Power of Data Cleaning

In recent times, significant advancements in large language models (LLMs) have been driven by pretraining models on vast corpora. While open-source LLMs, like LLaMA, have gained popularity through training on massive datasets containing 1 trillion tokens, they often underperform compared to proprietary models such as GPT family or Claude. In this blog post, we explore the reasons behind this discrepancy and delve into the significance of data cleaning in enhancing model performance.
Understanding the Quality of Text Data:
Text data can exhibit various quality issues, which can adversely impact the performance of language models. Cleaning the data and addressing these issues becomes crucial to optimize the output generated by LLMs. Let's take a closer look at how data can be of "bad" quality and explore techniques to clean it effectively.
Insights from Falcon LLM and Dataset Quality:
Recently, an open LLM called Falcon, developed by TIIUAE, was announced. The accompanying dataset paper contained valuable insights into improving dataset quality. However, in our case, we already had access to high-quality user-bot interaction data, eliminating the need to implement many of the methods proposed by the Falcon team.
Leveraging Techniques from Lee et al.:
Therefore, we decided to adopt the data cleaning techniques introduced by Lee et al (Falcon also used it!). Their work highlighted the detrimental impact of duplicate or near-duplicate user inputs on model performance. As our user-bot interaction data contained a significant number of such duplicates, addressing this issue became our primary focus.
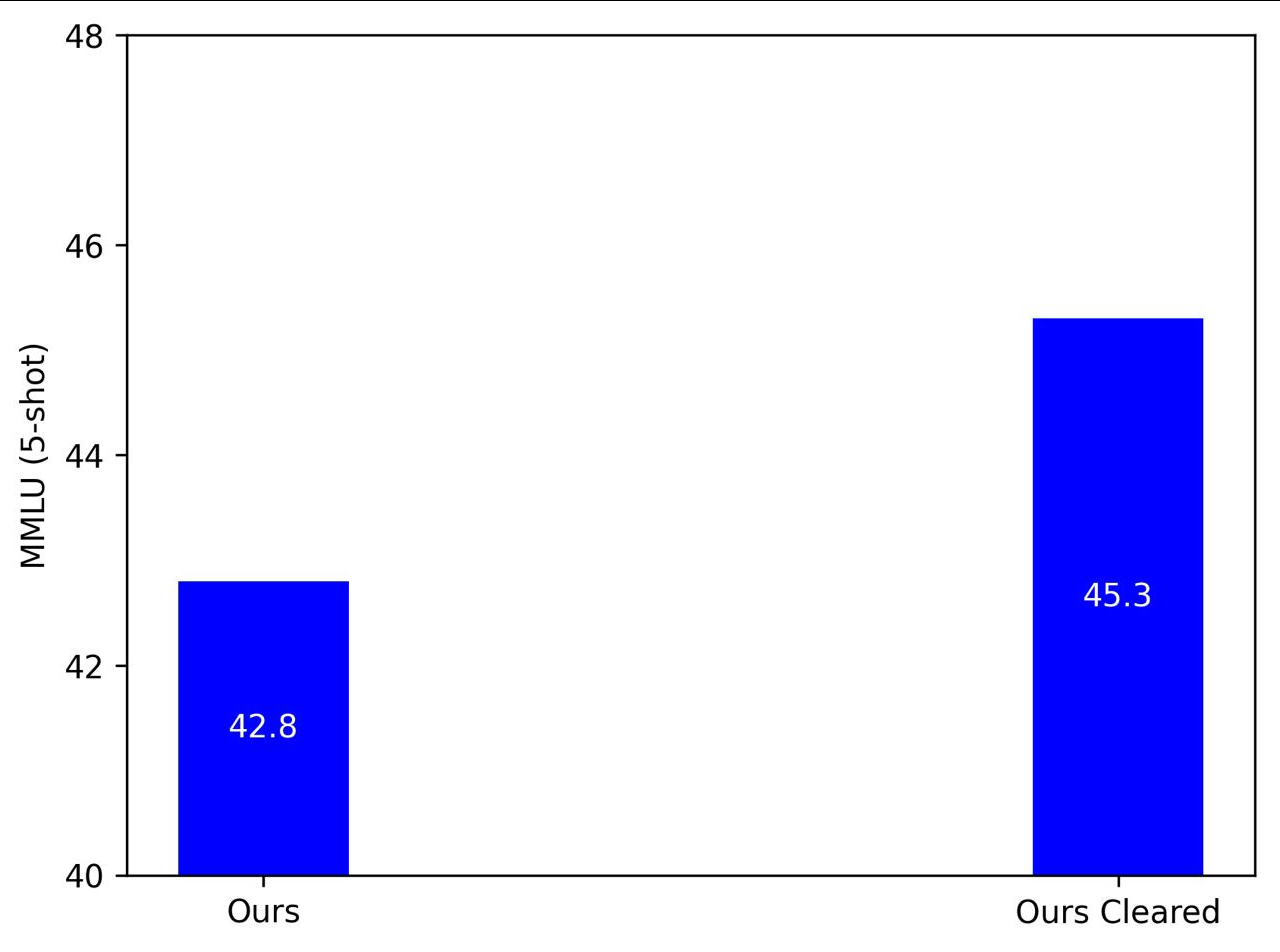
By diligently removing the duplicate or near-duplicate user inputs, we performed a thorough cleaning of our dataset. The impact of this cleaning process was remarkable, as our fine-tuned LLaMA 7B model showcased exceptional performance in various benchmarks, including MMLU and BBH.
Enhanced Performance through Answer Alignment Removal:
In addition to the duplicate removal, we experimented with eliminating aligned answers generated by the AI assistant. Phrases like "As an AI assistant, I cannot answer that question because it may contain harmful info..." were identified and removed from the responses. Surprisingly, this further improved our model's performance, resulting in an impressive MMLU score of 45.
Conclusion:
The recent advancements in large language models have highlighted the importance of data cleaning in optimizing model performance. By addressing issues like duplicate inputs and removing aligned answers, we witnessed significant improvements in the performance of our fine-tuned LLaMA 7B model. These findings emphasize the critical role of data cleaning techniques in enhancing the quality and effectiveness of large language models.